
**Индукция может быть полной и неполной. Полная индукция гарантирует истинность заключения, неполная — нет. Вот пример полной индукции. Предположим, в классе 30 человек, и все сдавали экзамен. Если у вас есть 30 посылок вида «Александр сдал экзамен», «Мария сдала экзамен» и аналогичные утверждения для всех остальных учеников, то вы можете сделать вывод: «Весь класс сдал экзамен», и это будет истинным заключением. Однако в большинстве случаев индукция является неполной — вам известно, что какой-то признак есть только у части элементов множества, и вы делаете вывод, что он имеется у всех его элементов. В этом случае истинность заключения не гарантируется. Например, если у вас есть информация только о 25 школьниках, сдавших экзамен, то вы можете предположить, что его сдали все 30 учеников, но это заключение уже носит вероятностный характер. Прим. пер.
Человек по своей природе плохо оперирует вероятностям и большими числами. Мы предпочитаем обращать внимание на информацию, которая кажется нам наиболее интересной, и игнорировать все остальное. И хотя люди всегда собирали и систематизировали данные, извлечь действительную пользу из обширных массивов информации удалось только благодаря теории вероятностей, открытой в середине XVII века и положившей начало современной статистике. С начала Нового времени статистика является важным инструментом научного познания мира, который позволил совершить значимые открытия в астрономии, биологии и медицине. В мире больших данных базовое понимание статистики и вовсе кажется необходимым. В книге «Искусство статистики. Как находить ответы в данных» (издательство «Манн, Иванов и Фербер»), переведенной на русский язык Евгением Поникаровым, британский статистик Дэвид Шпигельхалтер рассказывает о ключевых принципах и показателях, которые помогают извлекать из данных знания о мире и отвечать на вопросы о нем. N + 1 предлагает своим читателям ознакомиться с отрывком, посвященным тому, как на основании множества данных сделать правильный вывод.

Выводы из данных — процесс «индуктивного умозаключения»
В предыдущих главах предполагалось, что у вас есть какая-то проблема, вы получаете какие-то данные, смотрите на них и находите их сводные характеристики. Иногда ответ уже заключен в подсчете, измерении или описании. Например, если мы хотим знать, сколько людей в прошлом году обращалось в службу экстренной медицинской помощи, то данные дадут нам ответ.
Однако часто вопрос выходит за рамки обычного описания данных: мы стремимся узнать нечто большее, чем просто набор имеющихся у нас наблюдений, например, хотим делать прогнозы (что будет происходить с показателями в следующем году?) или сообщить о причинах (почему цифры растут?)
Прежде чем приступить к обобщению на основе данных, чтобы узнать что-то о мире за пределами непосредственных наблюдений, нужно задать себе вопрос: «Узнать о чем?». А это требует обращения к сложной идее индуктивного умозаключения.
Многие люди имеют некоторое смутное представление о дедукции благодаря Шерлоку Холмсу, использовавшему ее при поиске преступников*. В реальной жизни дедукция — это процесс применения правил логики для перехода от общего к частному. Если согласно законодательству в стране установлено правостороннее движение, то мы можем прийти к дедуктивному заключению, что в любой ситуации лучше ехать по правой стороне. Индукция работает наоборот: на основании частных случаев предпринимаются попытки сделать общие заключения. Например, мы не знаем, принято ли в каком-то сообществе целовать подруг в щеку, и пробуем это выяснить, наблюдая, целуют ли женщины друг друга один, два, три раза или не целуют вовсе. Принципиальное отличие индукции от дедукции состоит в том, что дедукция дает истинные заключения, а индукция — в общем случае нет**.
На рис. 3.1 индуктивное умозаключение представлено в виде диаграммы, показывающей шаги, связанные с переходом от данных к конечной цели нашего исследования. Как мы увидели, данные, собранные в ходе опроса, рассказывают нам о поведении людей в выборке; эту информацию мы используем для изучения поведения людей, которые могли бы стать участниками опроса, а уже из этого делаем некоторые предварительные выводы о сексуальном поведении в масштабе страны.
Конечно, было бы идеально, если бы мы могли сразу перейти от просмотра первоначальных данных к общим утверждениям о целевой совокупности. В стандартных курсах статистики предполагается, что наблюдения извлекаются совершенно случайно и непосредственно из интересующей нас совокупности.
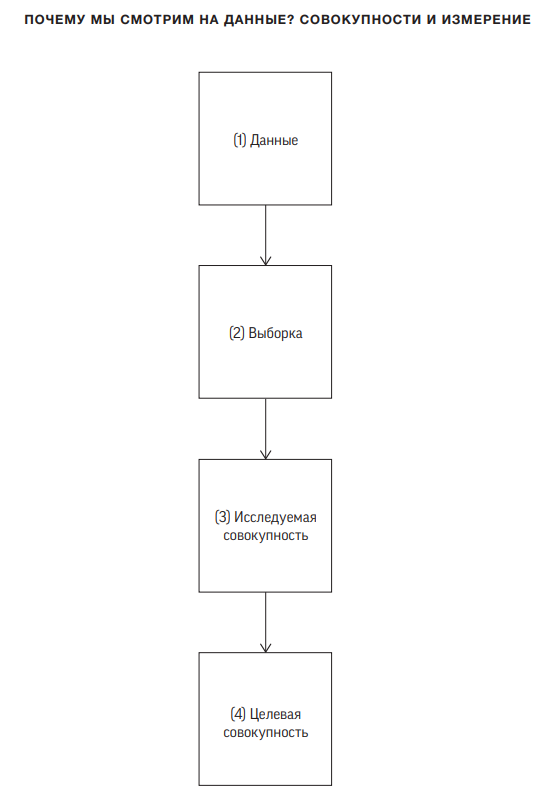
Рис. 3.1 Процесс индуктивного умозаключения: каждую стрелку можно истолковать как «говорит нам кое-что о…»
Однако в реальной жизни так бывает редко, поэтому нам приходится рассматривать всю процедуру перехода от первичных данных к конечной цели. При этом, как мы увидели на примере с исследованием Natsal, проблемы могут возникать на каждом этапе.
Переход от данных (этап 1) к выборке (этап 2) — это проблемы измерения. Является ли то, что мы фиксируем в своих данных, точным отражением того, что нас интересует? Мы хотим, чтобы наши данные были:
— надежными — в том смысле, что у них низкая изменчивость от случая к случаю и их можно считать воспроизводимыми и точными;
— достоверными — в том смысле, что вы измеряете именно то, что хотите, без какой-либо систематической ошибки.
Например, адекватность в опросе о сексе основывается на том, что люди на один и тот же вопрос каждый раз, когда их об этом спрашивают, отвечают практически одинаково, причем вне зависимости от интервьюера, настроения респондента или его памяти. Это в какой-то степени можно проверять, задавая в начале и в конце специальные вопросы. Качество исследования также требует, чтобы участники описывали свою сексуальную активность честно, а не систематически преувеличивая или преуменьшая свой опыт. Это довольно строгие требования.
Исследование станет недостоверным, если сами вопросы демонстрируют предвзятость в пользу конкретного ответа. Например, в 2017 году авиакомпания Ryanair объявила, что 92 процента ее пассажиров довольны предоставляемым сервисом во время перелетов. Но, как оказалось на самом деле, опрос об уровне удовлетворенности предусматривал только ответы отлично, очень хорошо, хорошо, удовлетворительно и окей***.
***После того как кто-то из Королевского статистического общества раскритиковал такие методы опроса, представитель руководства Ryanair Майкл О’Лири заявил: «95 процентов клиентов Ryanair никогда не слышали о Королевском статистическом обществе, 97 процентов не волнует, что там говорят, и 100 процентов сказали, что это звучит так, будто его участникам нужно забронировать недорогой отпуск с Ryanair». В другом современном исследовании Ryanair была признана худшей из двадцати европейских авиакомпаний (но у этого опроса свои проблемы с надежностью, поскольку он проводился как раз в то время, когда Ryanair отменила большое количество рейсов).
Мы уже видели, как форма подачи чисел (в положительном или отрицательном ключе) влияет на восприятие; точно так же формулировка вопроса может влиять на ответ. Например, в ходе опроса, проведенного в Великобритании в 2015 году, людей спрашивали, поддерживают ли они предоставление 16- и 17-летним подросткам права голосовать на референдуме о выходе из Евросоюза. Оказалось, что 52 процента выступают за и 41 процент — против. Таким образом, большинство людей поддержали это предложение, поскольку оно сформулировано с позиции признания и расширения прав молодежи.
Но когда тем же респондентам задали вопрос (логически идентичный предыдущему), поддерживают ли они уменьшение возрастного ценза для голосования на референдуме с 18 до 16 лет, доля сторонников этой идеи снизилась до 37 процентов, а против высказались 56 процентов. Таким образом, когда то же самое предложение было сформулировано в терминах более рискованной либерализации, большинство оказалось против. Мнение изменилось из-за простой переформулировки вопроса.
На ответы также может влиять то, что спрашивалось ранее, — механизм, известный в психологии как прайминг (или фиксирование установки, или эффект предшествования). Согласно официальным исследованиям благосостояния, 10 процентов молодых британцев считают себя одинокими, при этом в ходе онлайн-опроса службы «Би-би-си» этот ответ выбрало гораздо больше участников — 42 процента. Возможно, такое повышение показателя обусловлено двумя факторами: 1) самооценкой при добровольном «исследовании» и 2) тем, что вопросу об одиночестве предшествовал длинный ряд вопросов о том, испытывал ли респондент в целом недостаток дружеского общения, чувство брошенности, отстраненности и так далее. Возможно, все эти вопросы и побудили его дать положительный ответ на ключевой вопрос об одиночестве.
Переход от выборки (этап 2) к исследуемой совокупности (этап 3) зависит от фундаментального качества исследования, называемого внутренней валидностью: отражает ли наблюдаемая выборка то свойство группы, которое мы изучаем? Именно здесь мы приходим к ключевому способу для избежания искажений — случайной выборке. Даже дети понимают, что значит выбирать что-нибудь случайным образом — с закрытыми глазами сунуть руку в мешок с конфетами и посмотреть, какого цвета будет фантик у той, которую ты вытащил, или извлечь наугад номер из шапки, чтобы определить, кому достанется (или не достанется) приз или угощение. Этот метод тысячелетиями использовался для обеспечения справедливости — определения вознаграждения, проведения лотерей, назначения присяжных заседателей и прочего — и именовался жеребьевкой****. Применялся он и в более серьезных случаях — при выборе, кому идти на войну или кого съесть в спасательной шлюпке, затерявшейся в море.
****Не следует путать с гаданием [в оригинале используются сходные английские слова sortition и sortilege. Прим. пер.], представляющим собой форму предсказания, в которой очевидно случайные явления используются для определения божественной воли или будущего, что также известно как клеромантия. Примеры существуют во многих культурах, включая гадание с помощью чайных листьев, куриных внутренностей, библейское бросание жребия для определения воли Божьей или гадание по «Книге перемен» («И-Цзин»).
Джордж Гэллап, фактически разработавший в 1930-е годы научные методы исследования общественного мнения, предложил изящную аналогию для понимания ценности случайной выборки, сказав, что, если вы сварили большую кастрюлю супа, вам не нужно съедать его весь, чтобы узнать, достаточно ли в нем приправы. Хватит и одной ложки, но при условии, что вы хорошо все перемешали. Буквальное доказательство это утверждение получило в 1969 году во время лотереи, определявшей порядок призыва на войну во Вьетнаме. Сначала в рамках лотереи создавался упорядоченный список дней рождения, а затем те, чья дата рождения оказывалась в верхних строках списка, отправлялись во Вьетнам, и так далее. В попытке сделать эту процедуру справедливой было подготовлено 366 капсул с уникальной датой рождения в каждой. Предполагалось, что капсулы будут извлекаться из ящика наугад. Однако складывали их в коробку в соответствии с месяцем рождения и не удосужились должным образом перемешать. Это не привело бы к проблемам, если бы люди, доставая капсулы, запускали руку поглубже в коробку, но, как показывает видеозапись, они, как правило, брали капсулы сверху. В результате меньше всего повезло тем, кто родился в конце года: из 31 дня декабря были выбраны 26, в то время как из января — только 14 дней.
Идея надлежащего «перемешивания» имеет решающее значение: если вы хотите перейти от выборки ко всей генеральной совокупности, вы должны убедиться, что выборка репрезентативна. Наличие большого массива данных вовсе не гарантирует хорошую выборку и даже может вселить ложную уверенность. Например, на всеобщих выборах в Великобритании в 2015 году компании, проводящие опросы, с треском провалились, хотя их выборки включали тысячи потенциальных избирателей. Последующее расследование обвинило нерепрезентативную выборку, особенно для телефонных опросов, так как в большинстве случаев звонили только на стационарные номера и фактически на эти звонки ответили менее 10% абонентов. Вряд ли такую выборку можно считать репрезентативной.
Переход от исследуемой (этап 3) к целевой (этап 4) совокупности. Наконец, даже при превосходных измерениях и хорошей случайной выборке результаты по-прежнему могут не отражать того, что мы хотим исследовать, если нам не удалось опросить людей, в которых мы особенно заинтересованы. Мы хотим, чтобы наше исследование имело внешнюю валидность*****.
*****Это как раз и означает возможность распространения результатов конкретного исследования на более широкий класс объектов или ситуаций. В реальности обобщать полученный результат на любые популяции, любые условия и любое время вряд ли реально, поэтому говорят только о некоторой степени соблюдения внешней валидности. Прим. пер.
Крайнее проявление — это ситуация, в которой целевая совокупность состоит из людей, тогда как изучать мы можем только животных, например при анализе воздействия какого-то химического вещества на мышей. Не столь кардинальная разница будет в случае, если клинические испытания нового препарата проводились исключительно на взрослых мужчинах, а затем он использовался для женщин и детей. Мы хотели бы знать влияние на всех людей, но одним статистическим анализом тут не обойтись — мы неизбежно должны делать предположения и проявлять осторожность.
Подробнее читайте:
Шпигельхалтер, Д. Искусство статистики. Как находить ответы в данных / Дэвид Шпигельхалтер ; пер. с англ. Евгения Поникарова. — М.: Манн, Иванов и Фербер, 2021. — 448 с.